采收率算不准?来试试人工神经网络模型(上)-石油圈
| 所在地区: | 内蒙古-- | 发布日期: | 2019年8月5日 |
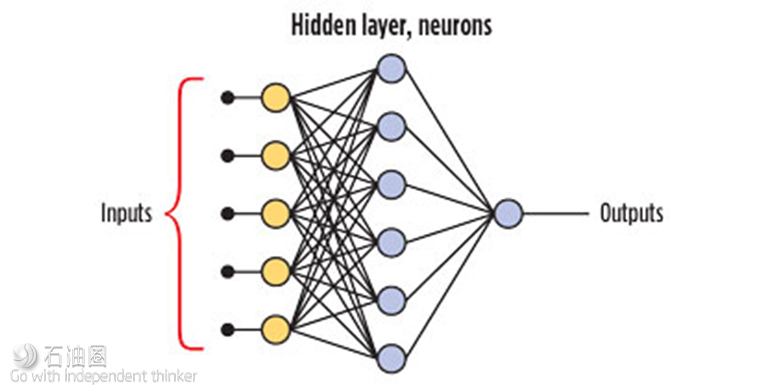
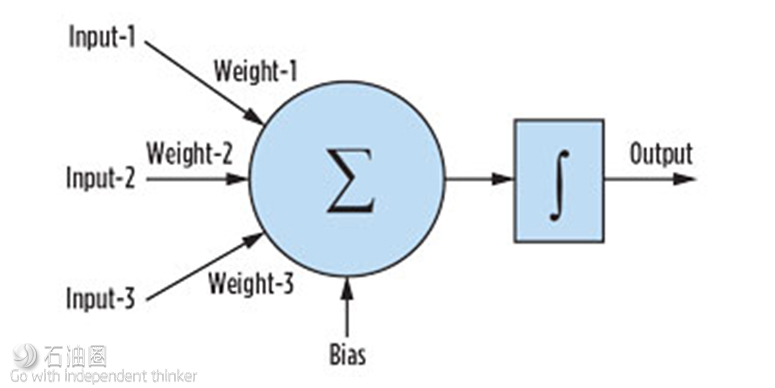
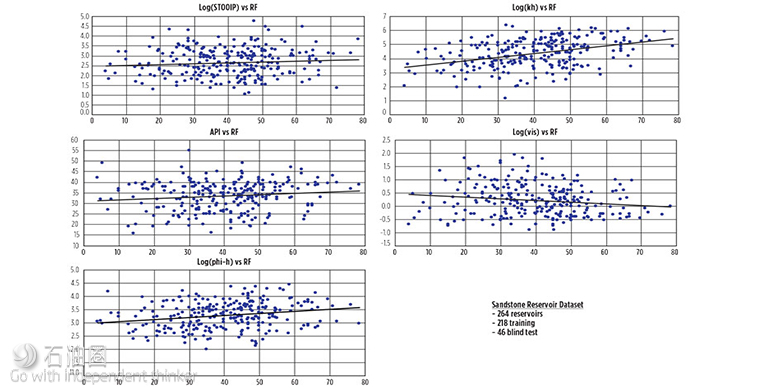
摘要:人工神经网络(ANN)是目前最为炙手可热的建模方法,如何用它来计算采收率?效果又会如何呢?本文将为您介绍ANN原油采收率模型的详细内容。 编译:TOM 人工神经网络(ANN)是一种信息处理系统,可模仿出人脑的思考过程。基于训练模式或大量数据,ANN能够进行机器学习。这些系统擅长于模式匹配、分类、数据聚类以及预测。ANN非常适合于复杂的非线性关系建模,例如水驱油藏中原油采收率的建模。 Neuro3是首个专为石油行业设计的、公开的通用人工神经网络,于2001年由美国能源部发布。虽然它只是个雏形,但仍然受到了广泛的关注。 神经网络生成的预测模型是一个多维函数,其中包含多个参数可调的元素。ANN模型中最重要的元素是神经元,它们包含在一个“隐藏层”中,如下图所示。神经元以数值输入的形式接收信息。然后,将这些信息与神经网络中的一组参数组合起来,以数值输出的形式生成结果。 ANN模型最常用的方法是反向传播、前馈与神经网络系统。其计算过程是前馈的,换句话说,也就是从输入层到隐藏层再到输出层。反向传播一般用于训练阶段。在该阶段,将计算输出值与期望值进行比较,然后输入误差值,以修改ANN中用于下一次迭代的权重。 神经网络的参数由两部分组成:一个是“组合函数”,它接受所有输入,并通过使用权重因子与偏差,来计算每个神经元的组合,最终形成一组净输入值;另一个是“传递函数”,它产生神经元输出。下图为单个神经元的前馈神经网络过程,其中Σ是组合函数,∫是传递函数。值得注意的是,预测神经网络中最常见的传递函数是双曲正切函数。 功能齐全的神经网络软件通常会与遗传算法、统计/线性回归、模糊逻辑相结合,以自动找到问题的最佳或接近最佳的解决方案。 任何ANN模型的有效性都取决于系统的训练程度。通常情况下,使用数据质量高的大型数据集进行训练,模型建立后,再使用不同的数据集来进行盲测试。ANN系统将训练数据集细分为训练集与验证子集。这与使用数据集来进行盲测试是不同的。验证子集仍然是训练数据集的一部分,并将之用于反向传播算法,因此它不是模型的独立测试。 开发一个神经网络通常有两个步骤:训练建立网络结构与权重因子,然后再进行预测。一旦经过训练,ANN就可用于预测新输入的数据。 原油采收率 人工神经网络特别适合于复杂非线性关系的建模,而传统的线性回归方法很难完成复杂非线性关系的建模。SPE发表了大量有关神经网络应用于石油行业的论文。在www.onepetro.org网站上搜索关键词“神经网络”,可以得到超过3900条参考文献。 利用开源的ANN系统,构建ANN原油采收率模型。市面上那些免费以及商业的ANN软件,都是基于名为OpenANN的开源ANN系统。该系统是由自由分布的神经网络库组成。 建立神经网络原油采收率模型。目前已经公布了几种用于预测采收率的经验公式。最常用的是API采收率小组委员会发布的采收率计算公式,该公式是基于70个水驱油藏的统计研究而得出的。该API采收率经验公式是针对水驱油藏,利用孔隙度、含水饱和度、地层体积系数、渗透率、水粘度、原油粘度、初始压力与枯竭压力等参数来计算采收率。 基于通用的油藏与采油工程原理,选用以下参数来建立ANN原油采收率模型:砂岩油藏、水驱、原始储量、孔隙度、渗透率、原油粘度、原油比重、产层有效厚度。虽然这些参数不是影响采收率的唯一参数,但这些参数被认为是影响油藏长期产量与采收率的主要因素。 在砂岩储层的ANN原油采收率模型中,拥有264个砂岩/碎屑岩、水驱/混合驱的油藏。这些油藏都拥有完整的数据集,包括采收率。将随机46个储层子集从完整数据集中删除,用作为盲测试。在剩余的218个油藏中,20%被用作为训练的验证数据。 显而易见,这些数据较为分散,范围太广。考虑到油藏采收率的影响因素,这并不出人意料。若要推导出具有普适性的原油采收率关系式,离散性是必须要面对的难题之一。离散性主要是储层平均参数与数据准确性所造成的。 为了使数据更有利于神经网络的使用,ANN的实际输入参数是:Log(原始储量)、Log(渗透率-深度)、Log(粘度)、Log(孔隙度-深度)以及原油API比重。将输入的数据进行对数处理,利用对数值确定出数据的线性范围,保证最大值与最小值在合理范围内。在数据应用于ANN之前,先进行数据的预处理或使数据线性化。 如下图所示,每个输入数据集在采收率方面都呈现出近似线性趋势。这些明显的趋势有助于神经网络系统找到最佳解决方案。原始的数据集中包含有38个碳酸盐岩/白云岩油藏,后来将它们从302个油藏的总数据集中剔除出来。因为碳酸盐岩油藏的采收率,始终是ANN模型中的异常值。这是由于碳酸盐岩油藏含有大量天然裂缝,会影响油藏的最终采收率。 明天的文章将为大家带来ANN砂岩油藏采收率的建模方法与参数选择,敬请期待! Neural network-derived model accurately predicts oil recovery in water-drive reservoirs Artificial neural networks are information processing systems constructed to mimic procedures that resemble those of the human brain. They have the ability to learn procedures from training patterns or data. These systems excel at pattern matching, classification, data clustering and forecasting. Artificial neural networks are well-suited for modeling complex non-linear relationships, including the modeling of oil recovery factors in water-drive reservoirs. Image: Apache Corp. This theorum states that any continuous function that maps a set of real numbers, to another set of real numbers, can be approximated with a certain degree of accuracy by a feed-forward ANN with a single hidden layer and a finite number of hidden units, which contain non-linear transfer functions. The first publicly available, general-purpose ANN designed specifically for the oil industry was called Neuro3 and was released by the DOE in 2001.2 It was rudimentary, but is still relevant. The number of parts in the Vx Omni flowmeter has been reduced by approximately 66%, compared with previous-generation technologies. More than 90% of these components, including the most advanced instrumentation, are standardized for pressure rating, process fluids compatibility, temperatures, flow rates, and water depth. An ANN generates a predictive model as a multidimensional function containing elements with adjustable parameters. The most important elements of an ANN model are the neurons, which are contained in a “hidden layer,” Fig. 1. The neurons receive information in the form of numerical data input. This information is then combined with a set of parameters within the neural network to produce a result in the form of a numerical output. Most common ANN models use a back-propagation, feed-forward, neural network system. The calculation procedure is feed-forward; in other words, from input layer through hidden layers to output layer. The back-propagation occurs during the training phase, where the calculated outputs are compared with the desired values, and the errors are input to modify the weights used in the ANN for the next iteration. The neural network parameters are made up of two components: a “combination function,” which takes all the inputs and produces a set of net input values by calculating the combination of each neuron using a weight factor and a bias; and a “transfer function” which produces the neuron output. Figure 2 presents a single neuron feed-forward neural network process, where ∑ is the combination function and ∫ is the transfer function. It should be noted that the most common transfer function in predictive neural networks is the hyperbolic tangent (tanh). Full-featured neural network programs are normally combined with genetic algorithms, statistics/linear regression, and fuzzy logic to automatically find optimal or near-optimal solutions for the problem. The validity of any ANN model is dependent on how well the system has been trained. Normally, a large dataset of well-behaved data is used for training, and a different set of data is used as a blind test after the model is built. ANN systems will subdivide the training data set into a training set and a validating subset. This is not the same as using a data set as a blind test. The validating subset is still part of the training subset and is used in the back-propagation algorithms, so it is not an independent test of the model. There are two steps in the development of a neural network: Training establishes the network structure and, the weight factors for the network and therefore, always occurs before the prediction step. Once trained, the ANN can be used to predict output data from new input. OIL RECOVERY FACTOR Artificial neural networks are particularly well-suited for modeling complex non-linear relationships, which cannot be easily patterned by traditional linear regression methods. SPE has published numerous papers on the use of neural networks in the oil industry. A search in www.onepetro.org, using the keywords “neural networks,” yields over 3,900 references. The ANN oil recovery factor model was developed, using an open-source ANN system. There are free and commercial ANN programs available that are based on the open-source, OpenANN system, comprised of freely distributed neural network libraries. Building the ANN Oil RF model. There are several empirical relationships that have been published for recovery factor predictions. The most common are the equations for recovery efficiency published by the API Subcommittee on Recovery Efficiency, developed from a statistical study of 70 water drive reservoirs. The empirical API oil recovery factor equation for water drive (WD) oil reservoirs, for a given porosity (Ф), water saturation (Sw), formation volume factor (Boi), permeability (k), water viscosity (μw), oil viscosity (μoi), initial pressure (Pi) and abandonment pressure (Pab) is as follows: An API RF equation description, and how it can be converted into a probabilistic determination of recovery factor, is described in the literature. Based on general reservoir and production engineering principals, the parameters used to build the ANN Oil RF model were: sandstone reservoir, water drive, original oil in place (STOOIP), porosity (Ф), permeability (k), oil viscosity (μ), oil gravity (API) and net pay (h). Although these are not the only parameters that impact recovery, these parameters were considered to be the major components impacting long-term production and recovery of oil from a reservoir. For the sandstone reservoir ANN Oil RF model, 264 sandstone/clastic water drive/combination drive oil reservoirs were available with complete data sets, including recovery factors. A random subset of 46 reservoirs was removed from the full data set, to be used as a blind test. Of the remaining 218 reservoirs, 20% were used as validating data for training. Figure 3 presents the data for the sandstone reservoir data set. After a visual inspection, it becomes apparent that the data have a large scatter and a wide range. This is not unexpected when considering oil reservoir recovery factors. The scatter is one of the problems with trying to generate an oil recovery factor correlation that is universally valid. The scatter is predominantly caused by using average reservoir parameters, as well as the accuracy of the data. To make the data more conducive to neural network use, the actual inputs to the ANN were: Log(STOOIP), Log(kh), Log(viscosity), Log(phi-h) and Oil API. The logarithm of the input data was used to linearize the data range and to place the maximum and minimum in a reasonable range, as well as to pre-process/linearize the data prior to use in the ANN. Figure 3 shows that each input data set exhibits an approximate linear trend in terms of recovery factor. These apparent trends help the neural network system find an optimal solution. The original data set included 38 carbonate/dolomite oil reservoirs. These data were removed from the gross data set of 302 reservoirs, because the recovery factors calculated for the carbonate reservoirs were always the outliers in the resulting ANN model. This was the result of carbonate reservoirs containing natural fractures, which will impact the ultimate recovery from these reservoirs.

按照客观、公正、公开的原则,本条信息受业主方委托独家指定在中国建设招标网 www.jszhaobiao.com 发布
注册会员 享受贴心服务
标讯查询服务
让您全面及时掌握全国各省市拟建、报批、立项、施工在建项目的项目信息。
帮您跟对合适的项目、找对准确的负责人、全面掌握各项目的业主单位、设计院、总包单位、施工企业的项目 经理、项目负责人的详细联系方式。
帮您第一时间获得全国项目业主、招标代理公司和政府采购中心发布的招标、中标项目信息。
标讯定制服务
根据您的关注重点定制项目,从海量项目中筛选出符合您要求和标准的工程并及时找出关键负责人和联系方式。
根据您的需要,向您指定的手机、电子邮箱及时反馈项目进展情况。